Entscheidungen in der industriellen Welt darüber zu treffen, mit welchem Technologielieferanten man zusammenarbeiten möchte, ist eine harte Geschäfts- und damit Karriereentscheidung - aus all den Gründen, die Sie genau kennen. Bei der Suche nach der bestmöglichen Entscheidung haben wir das Glück, dass der Industriesektor schon immer sehr konservativ war, was die Geschwindigkeit der Einführung neuer Technologien angeht. Die Kosten, die selbst mit einem kurzen ungeplanten Stillstand der Produktionsanlage verbunden sind, haben für eine sehr vorsichtige und detaillierte Analyse vor der Inbetriebnahme gesorgt. Hinzu kommt seit jeher der sehr proprietäre Charakter der von den wichtigsten Anbietern angebotenen Steuerungssoftware. Proprietäre Software ist naturgemäß innovationshemmend.
Dieselbe konservative Sichtweise erlaubt es uns, auf andere Sektoren zu schauen, die die Technologie bereits übernommen haben, so dass wir entscheidende Hinweise für unsere Entscheidungen sammeln und die möglichen zukünftigen negativen Ergebnisse reduzieren können.
Das Internet der Dinge bietet uns diese Möglichkeit. Mit einem Argument von Peter Levine, einem hoch angesehenen IoT-Investor, möchte ich Ihnen zeigen, wie das geht.
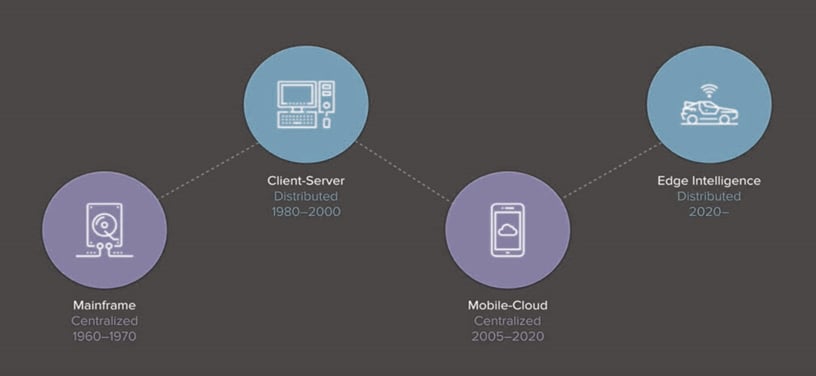
Die heutige IT-Welt baut auf einem zentralisierten Modell auf.
- Wenn Sie eine SMS von Ihrem Smartphone an meines senden, geht die Nachricht an eine zentralisierte Cloud, die sie dann an mein Smartphone weiterleitet.
- Wenn Sie bei Google nach irgendetwas suchen, geht die Anfrage an die zentralisierte, cloud-basierte Datenbank von Google, die das Ergebnis zurück auf Ihren Bildschirm sendet.
Dieses Modell ist das jüngste in einer Serie seit Beginn des Computerzeitalters.

Wenn Sie so alt sind wie einige von uns hier bei EXOR International, können Sie sich an die Mainframe-Zeit erinnern, in der es vielleicht 10.000 Großrechner auf der Welt gab, von denen jeder so groß war wie Ihr jetziges Zuhause und jeder einen Termin benötigte, um eine Arbeit damit zu erledigen. Ein stark zentralisiertes Modell.
Mit dem Aufkommen des PCs in den 1980er Jahren gingen wir dann langsam zu einem stärker verteilten Modell über, bei dem das Alleinstellungsmerkmal darin bestand, dass Daten und Rechenleistung im PC verfügbar waren, so dass man für 90 % der erforderlichen Arbeit keine Großrechner einsetzen musste.
Mit der zunehmenden Nutzung mobiler Geräte und insbesondere von Smartphones kehrten wir zu einem zentralisierten Modell zurück.
Doch mit dem Internet der Dinge haben wir zum ersten Mal in der Geschichte der Computer begonnen, Echtzeitdaten zu sammeln, und die Menge dieser Daten ist gewaltig: ein Tesla-Auto produziert über 10 GB Daten alle 1 km und ein Jumbo-Jet produziert über 20 Terabyte pro Flugstunde. Dies sind enorme Datenmengen, die die Fähigkeit der Cloud, realistisch zu arbeiten, in Frage stellen.
Neben der Menge der produzierten Daten werden auch die IoT-Edge-Geräte selbst schnell immer anspruchsvoller. Was als autonome Autos begann, bewegt sich zu Drohnen, Robotern und anderen IoT-Geräten. Aufgrund der Latenzzeit des zentralisierten Cloud-Modells als SMS- oder Google-Anfrage muss die Verarbeitung der Daten an der Edge erfolgen. Zum Beispiel wird ein Tesla-Auto, das ein STOPP-Schild sieht, bis zum Abschluss der Analyse zehn Personen überfahren haben und mit fünf Fahrzeugen zusammengestoßen sein, bis die Anweisung aus der Cloud zurückgekehrt ist, um ihm zu sagen, dass es anhalten soll. Daher werden diese Edge-Geräte mit Rechenleistung belastet und sind quasi selbst Rechenzentren.
Die Kombination aus massiven Echtzeitdatenmengen und der Forderung nach Echtzeitverarbeitung an der Edge führt direkt vor unserer Nase zu einer Rückkehr zu einem verteilten Modell. In diesem Modell wird die Cloud der Ort, an dem das Lernen stattfindet, und der letzte Punkt der langfristigen Datenspeicherung, wobei der größte Teil des Verarbeitungsbedarfs an der Edge liegt. Peer-to-Peer-Kommunikation, bei der Geräte mit anderen Geräten sprechen und interagieren, wird die Herausforderungen und Möglichkeiten in dieser neuen Ära schaffen, besonders wenn man die Sicherheitsimplikationen dieses Modells berücksichtigt.
In der industriellen Welt treten wir in die Ära des zentralisierten Modells mit mehr Marktübereinstimmung über die für die Einführung einer industriellen Cloud erforderlichen Spezifikationen ein.
Heute besteht das vorherrschende Marktbedürfnis darin, Daten in einer immer noch sehr unterschiedlichen Altfabrik-Protokollumgebung zu erfassen und diese Daten dann zu speichern und zu visualisieren, ggf. manipuliert zu verwertbaren KPIs. Es gibt nur sehr wenige industrielle Clouds auf dem Markt, die diese Anforderungen erfüllen, und dennoch kann Ihre Entscheidung, welche Cloud Sie einsetzen möchten, nicht nur Ihre aktuellen Unternehmensanforderungen erfüllen. Angesichts dessen, was wir aus den oben erwähnten Änderungen des IoT-Modells gewinnen können, können wir versuchen, die möglichen zukünftigen Ergebnisse der industriellen Technologie zu reduzieren, denen der heutige Kauf nicht gerecht wird:
- Da die Geräte an der Edge immer ausgeklügelter werden, wäre es sehr nützlich, wenn der Cloud-Anbieter ein bewährter, langfristiger Innovator für immer intelligentere Edge-Geräte wäre.
- Da die Cloud immer mehr zu einem Langzeitspeicher und Lernort wird, wird die Peer-to-Peer-Kommunikation zunehmen. Einen Cloud-Provider zu haben, der eine offene Konnektivitätssoftware im Web betreiben kann, die jedem Industrieprotokoll gegenüber agnostisch ist, würde zukünftige Risiken reduzieren.
- Was auch immer Ihr Unternehmen heute verkauft, es ist fast sicher, dass mit der Zeit intelligente Sensoren in diesem Produkt platziert werden. Sinnvoll wäre es, wenn der Cloud-Provider bis hinunter zur nanoSOM-Ebene zu produzieren versteht, damit die Daten der Sensoren leicht in Ihre Cloud-Lösung integriert werden können.



